
Ok, this is really basic, but I finally got to reading about Retrieval-Augmented Generation. The concept is simple, but I wanted to sketch how RAGs work in just a teeny bit more technical detail than most diagrams out there:
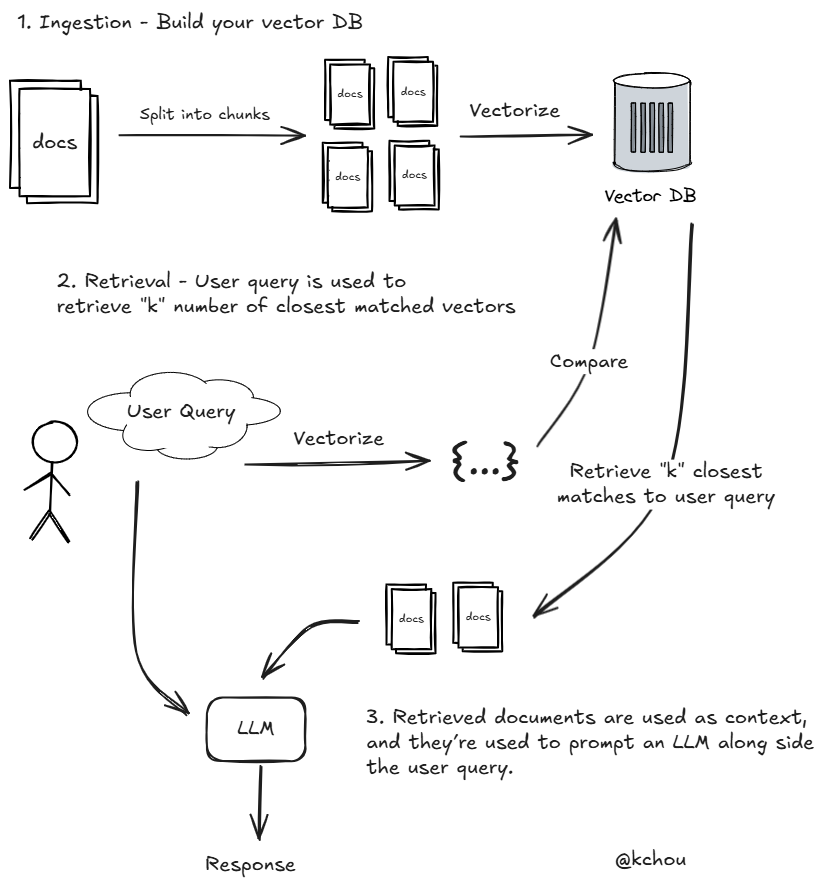
Q - Why do you split your documents into chunks?
A - This limits the context window size we search over. A smaller chunk size makes our context more focused and accurate. But too small of a chunk may not contain enough context to answer user queries. Play around with the chunk size to find the right one for your application.
Q - What’s special about vector databases?
A - Vector DBs are designed to optimize similarity searches. Since RAGs are designed to retrieve closest matches (highest similarity vectors), efficiently designed DBs help improve overall system performance.
Q - How many similar vectors should I retrieve?
A - The number of vector retrived is normally denoted as “k”. For simple queries, smaller “k” might be sufficient, while complex queries might require a larger “k” to ensure all relevant information is captured. You might want to dynamically determine “k” based on query complexity.
Ok, that was helpful for my own learning. Maybe it helped you too?
Further reading: How do vector DBs work? It’s not k-nearest neighbors