
In the Spring of 2023, I had the privilege to serve as a project mentor for the Erdos Institute, a program designed to help Ph.Ds transition into the industry. Twice a year, the Erdos institute holds a project-based data science bootcamp for recent Ph.D graduates. The short program is designed to teach the basics of data science and prepare them for work in the industry. At the end of the program, teams present on their project and are judged by a panel of data science professionals on both technical and non technical aspect of the work. I am proud to say that my team was awardest 1st place among 33 teams. You can find their incredible work on github.
The project
Overcoming Bias in Pulse Oximetry
Given my background in medical devices and experience in the non-profit sector, I suggested my team to tackle the serious and pressing issue of inaccuracies in the arterial oxygen saturation (SaO2) measurements in dark-skinned individuals.
During the COVID19 pandemic, the use of pulse-oximetry became common place. Its widespread use made the public aware of an issue that was known to a niche community of researchers as early as 2005 - pulse oximeters tend to overestimate the amount of oxygen a patient with darker skin may actually have in their blood. And I don’t just mean Black patients, but also Asian and Hispanic patients (more). This is especially problematic during the pandemic. Hospitals were operating over capcity, and can only afford to give oxygen treatment to patients with a dangerously low level of blood oxygen. However, the existing oximeters tend to overestimate the amount of oxygen a patient with darker skin may actually have in their system. Consequently, these patients often would not receive critical oxygen treatment in time, and has increased risk of going through hypoxia.
The Issue with Pulse Oximetry
Pulse oximeters use amplitude of the absorbances (A) at the red and infrared (IR) to calculate a Red:IR Modulation Ratio ( \(R\) ):
\[R = \frac{A_{red,AC}/A_{red,DC}}{A_{IR,AC}/A_{IR,DC}}\]then, a calibration curve is used to map \(R\) to SaO2. The calibration curve is typically generated empirically by measuring \(R\) in healthy volunteers whose SaO2 were altered from 100% to approximately 70%*. And this is where the main issue lies - the curve is calibrated toward mainly those with light skin. Of course, this is not done intentionally, but most likely because there were not enough diversity in the dataset when the calibration curve was constructed.
*The actual calculation from absorbance ratios to SaO2 is a bit more complicated than this. For those interested, I suggest reading the introduction of Chan, Chan, and Chan, 2013.
Racial Bias? or Poor Training Data?
In 2020, an image “enhancing” StyleGAN famously took a pixelated image of Barack Obama and turned him caucasian. From an ML perspective, the likely culprit is the lack of African faces in the training set. My guess is that a similar issue must have had happened during the construction of the pulse oximetery calibration curve.
The team quickly confirmed this during the EDA phase of the project. Inspecting the dataset revealed that although dark-skinned individuals have higher rate of “hidden hypoxemia”, the number of dark-skinned individuals were much lower than light-skinned individuals. Indeed, the large skew in distribution of patient skin tones was the main challenge the team faced.
The Approach
The biggest question from extremely technical individuals is often about how to technically approach the problem. I advised the team on some common approaches used to tackle uneven distribution of training data:
- Undersampling the over-represented class
- Oversampling the under-represented class, e.g., SMOTE
- Modifying weights and costs during training
However, more than building a perfect model, I advised the team that was even more important to tell a good story at the end of the bootcamp. The team had two short weeks to tackle this problem, and I reminded them that their results won’t be perfect. What I wanted to know, as an outsider, was:
- What was the issue?
- Why was it important?
- What was the approach?
- What is next?
And remember, the audience really don’t care about the technical details. All they care about is: “so what?”
Reflections
The judges recognized that the team tackled a challenging problem, and told a compelling story. I am proud of how well the team communicated and worked together. What really wowed me was the idea to publish the model on HuggingFace. With my academic training, I would be reluctant to show off an imperfect product, but this bold move was exactly what works in industry. I think the judges recognized this as well.
So, what’s next for the team? When asked, “What kind of data science are you interested in”, most fresh grads would feel at a loss. After all, “Data Science” is such a broad term. There are two important ideas that fresh grads must keep in mind:
First, not all firms need data scientsts. Not all companies need to use AI/deep learning. Also, companies cannot build AI/deep learning models without these other components.
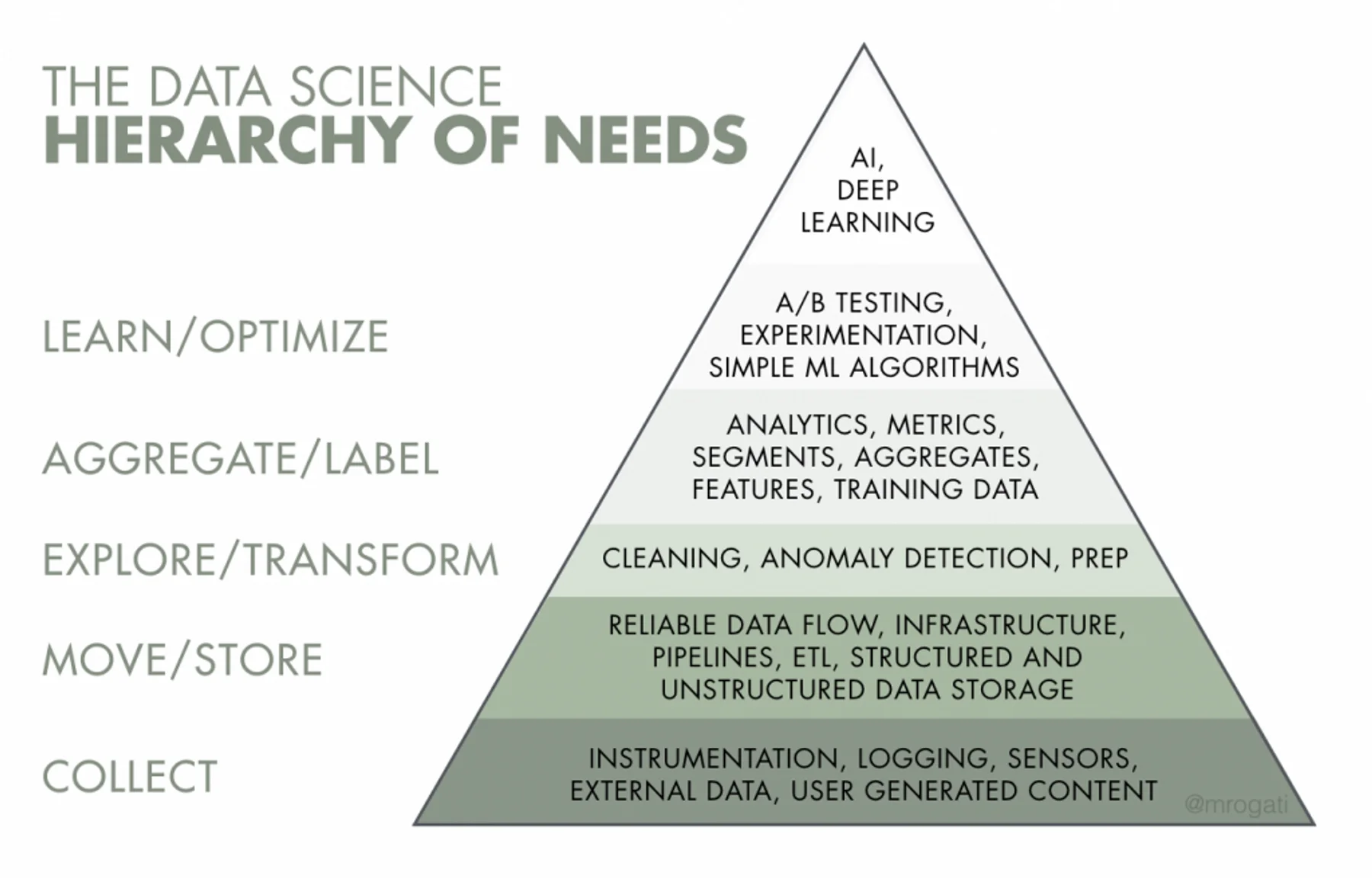
Second, depending on your interests, maybe a “data scientist” role isn’t what you’re looking for. Although they’re on the opposite side of the spectrum, I find myself leaning toward both Data Analyst and ML Engineer roles.

Best of luck to all the new grads out there.